
IoT検定おすすめ問題集・テキスト・参考書ランキング – 合格勉強法

コンテンツ
「ITに関する資格を取得したい」
「近年よく聞くIoTについて勉強してみたい」

このように考えている方もいらっしゃるのではないでしょうか。
そこでおすすめなのが「IoT検定」という資格です。取得することで、IoT、AI、ビッグデータなどの知識やスキルがあることを証明することができます。
本記事では、IoT検定の合格を目指す上でおすすめの参考書をご紹介していきます。
IoT検定について
IoT(Internet of Things)とは、モノとモノをインターネットでつなげる仕組みのことです。さらに、つなげるだけでなく、そこからデータを収集・分析することでシステムを向上させていくことが可能です。
本資格は、IT関連の仕事をしている方はもちろん、今後は様々な分野でも役立つと考えられるので、幅広い業種の方におすすめの資格です。
それでは、IoT検定の概要に関して以下にまとめていきます。
| ユーザー試験 | レベル1試験 | |
| 受験資格 | なし | |
| 試験方式 | 三肢択一式(CBT方式) | 四肢択一式(CBT方式) |
| 問題数 | 48問 | 70問 |
| 試験時間 | 40分 | 60分 |
| 受験料 | 8,800円 | 11,000円 |
| 合格基準 | 66%以上の正解で合格
正答率に応じてグレード認定 ・グレードA=86〜100% ・グレードB=76〜85% ・グレードC=66〜75% |
60%以上の正解で合格 |
| 出題分野 | ・IoT全般
・戦略とマネジメント ・産業システム ・ネットワーク ・デバイス ・プラットフォーム ・データ分析 ・セキュリティ |
・戦略とマネジメント
・産業システム ・法務 ・ネットワーク ・デバイス ・プラットフォーム ・データ分析 ・セキュリティ |
IoT検定は、レベル別に4つの階級に分かれていて、低い方から「ユーザー試験」「レベル1試験」「レベル2試験」「レベル3試験」となっています。しかし、現在試験が実施されているのはユーザー試験とレベル1試験のみとなっており、残りの2種に関しては順次実施予定です。
試験方式は、ユーザー試験が三肢択一式、レベル1試験が四肢択一式のCBT方式です。全国の試験会場で年間を通して行われており、1度受験しても30日経つと再受験が可能になります。
ユーザー試験では66%以上の正解で合格ですが、正答率に応じてグレード認定がされます。レベル1試験ではグレード認定という制度はなく、正答率60%以上で合格となります。
IoT検定では、システムの構築や保守・運用を行うエンジニアだけでなく、IoTに関するプロジェクトの企画担当者、IoTを利用したデータ分析を行う方など、幅広い方が受験対象となっています。そのため、出題範囲も技術的なことだけでなくマネジメントなどに関する内容も含まれます。
IoT検定では、合格率は公開されていません。しかし、参考値として平成28年5月〜平成30年6月の2年間で認定されたIoTプロフェッショナル・コーディネータ(レベル1試験)の受験者数と合格者数が公開されており、その合格率は58.3%となっています。
IoT検定の対策ポイント
IoT検定では合格率が公開されていませんが、難易度的には他のIT系資格と比べて易しい部類に位置すると言われています。学習期間の目安は1〜2ヶ月程度です。
それでは、IoT検定の対策ポイントについて見ていきましょう。
IoT検定は2016年から実施されている比較的新しい資格試験です。そのため、あまり専用の参考書や問題集などは発行されていません。また、過去問も公開されていません。
しかし、試験難易度はそこまで難しくないので汎用的なIoTの知識を身につけることで対応できます。IoTの関連資格のテキストを使って知識を身につけていくのも良いでしょう。
また、IoTを利用する上ではデバイス、ネットワーク、データ分析、セキュリティなどの多岐にわたった知識が必要となるので、試験でも広く問われます。既にIoTのシステムに携わっている場合でも初見の分野があるかもしれないので、学習計画を立てる前にきちんと試験範囲を把握しておく必要があります。
IoT検定のおすすめ参考書
それでは、IoT検定の対策におすすめの参考書をご紹介します。
1.図解即戦力 IoTのしくみと技術がこれ1冊でしっかりわかる教科書 IoT検定パワーユーザー対応版
IoT検定の公式テキストです。教科書と問題集が一体となっているので、この1冊で対策を完結することができます。また、1番難易度の低いユーザー試験にも対応しているため、イラストを多用してわかりやすく解説されています。初学者の方にもおすすめの一冊です。
2.IoTの全てを網羅した決定版 IoTの教科書
IoT検定のレベル1試験に対応したテキストになります。幅広い内容から出題されるIoT検定の試験範囲を網羅しています。漏れなく範囲内の内容を学びたい方向けの参考書です。
3.問題を解いて実力をチェック IoTの問題集
上記で紹介したIoTの教科書の姉妹本の問題集です。教科書で学んだ内容がどの程度身についているかをチェックできます。IoT検定では過去問が公開されていないので、演習形式で学習ができる貴重なテキストです。
IoT検定のおすすめ参考書のまとめ
ここでは、IoT検定のおすすめ参考書をご紹介しました。
IoTは今後様々な分野で活用が期待できる技術なので、どんな業界の方でも取得しておくと利用できるチャンスがあるかもしれません。中でもIoT検定は関連資格の中でも比較的易しい資格なので、IT関連の学習の足がかりとしてもおすすめです。
是非この機会にIoT検定の受験を検討してみてはいかがでしょうか。
Part1 IoT検定の過去問・サンプル練習問題(一問一答無料)
Part2 – IoT検定の過去問・サンプル練習問題(一問一答無料)
問題16 ★★★
GPIOを通じたPWM信号の生成について、(A)~(F)に当てはまる言葉。
例えば、GPIO上でSoC内の(A)や(B)(順不同)などを使って時分割制御を行い、(C)の(D)比を時間方向で制御することでPWM信号を生成することが可形である。PWM信号はモーター、スピーカーなどの(E)負荷に対する出力の場合(F)の近似として考えることが可能。
- 空乏層
- 白色ガウス雑音
- タイマー
- 電子
- デューティー
- 誘導性
- アスペクト
- ADコンバーター
- 正弦波
- カウンター
- 低周波駆動
- 矩形波
- ランプ波
- ピンクノイズ
正解A・B: 3・10(順不同)、C: 12、D: 5、E: 6.F: 9
GPIO(General Purpose I/O)はマイクロコントローラーの基本的な入出力で、プログラム上からは単なるON/OFFで制御できる。このON/OFFのタイミングを、マイクロコントローラー内のタイマーとカウンターを使って時分割制御することで、矩形派のデューティー比を任意に変化させ、PWM(Pulse Width Modulation)信号を生成。
信号を受ける負荷がモーターやスピーカーなど、誘導性負荷である場合には、正弦波の近似として考えられる。冷却ファンの制御ICでは、デジタル制御可能な複数のPWMチャネルを持つことで、システムを速やかに目標温度へ遷移。
問題17 ★★
アナログ信号とデジタル信号との変換に関する正しい説明。
- D/A変換は量子化、符号化、サンプリングの順に行われる。
- サンプリング定理により、最大周波数以上の周波数でサンプリングする。
- 電話などの音声デジタル化で8ビット量子化、8kHzサンプリングを行い、2進数に符号化した場合、64kbpsのビットレートになる。
- デジタル値からアナログ電圧に変換するためにA/D変換回路が使われる。
正解3
アナログ電圧からデジタル値への変換をA/D変換やA/D、ADCと呼び、デジタル値からアナログ電圧への変換をD/A変換と呼びます。A/D変換を行う装置をA/D変換器やA/Dコンバーターと呼ぶ。
A/D変換は時間軸での離散化であるサンプリング、電圧軸での離散化である量子化、離散化した値の符号化の順で行われる。量子化と符号化は同時に行われる場合も。符号化では2進数が使われることが一般的。
サンプリング周波数はA/D変換する信号が持つ最大周波数の2倍以上を使うと元の信号に復元できる。=サンプリング定理
量子化では、サンプリングしたアナログ信号を量子化単位電圧の整数倍の数値に丸める処理などが行われるため誤差が生じる。 =量子化誤差
音声のデジタル化では8ビット量子化、8kHzサンプリングがよく使われ、この場合のビットレートは8ビット×8kHz=64kbps。
∴正解は選択肢3。

問題18 ★
温度測定に使われるセンサーに関する正しい説明。
- 熱電対を使った温度センサーは、異なる種類の金属を使うもので、取り扱いが簡単。
- 白金抵抗温度計は温度による白金の抵抗変化を使うが、高精度な測定には不向き
- サーミスターは温度で抵抗値が変化する酸化物半導体で、温度に抵抗値が正比例する特性を持つものが温度センサーとしてよく使われる。
- IC温度センサーは、半導体温度センサーなどを内蔵したICで、デジタル信号を出力くするものや温度に比例したアナログ電圧を出力するものがある。
正解4
熱電対は、ゼーベック効果を利用した温度センサー。
ゼーベック効果:両端を接続した異なる金属線の接続点の温度差によって電位差が生じる効果のこと(図1)。
金属の中の電子(自由電子)は高温側から低温側に流れる性質がある。その大きさは金属の種類によって異なるので、2種類の金属の高温側を接続すると、高温側と低温側の温度差によって低温側に電位差が生じる。なお、逆方向に電流が流れる物質もある。
この電位差から温度差を測定できるので、低温側の温度を基準として高温側の温度を測定することも可能。工業炉の温度測定などでよく使われる。低温側の基準として、氷を使った0℃の基準温度(アイスボックス)を用意するか、他のセンサーで温度を測定。
従って、取り扱いが簡単ではない。
白金温度抵抗体は温度による抵抗値の変化の直線性が良いので、精密な温度測定に使われる。熱電対と比較すると低温での温度測定に使用されるが、応答性で劣る。
サーミスターは温度で抵抗値が変化する酸化物半導体。温度特性により、NTC(Negative Temperature Coefficient)、PTC(Positive Temperature Coefficient)、CTR(Critical Temperature Resistor)がある(図2)。NTCは負の温度特性を持ち、-50~+400℃程度の温度範囲において安価でよく使われる。PTCは正の温度係数を持ち、-50~+150℃程度の温度範囲を持ち、主に過熱防止に使われる。CTRは急峻な負の温度特性で、-50~+150℃程度の温度範囲。
ICを内蔵した温度センサーでは半導体(Thermal diode)の温度特性を内部回路で補正し、温度に比例した電圧を出力したり、デジタル信号を出力したりする。半導体を使用しているので測定範囲はあまり広くなく、エアコンの温度測定やパソコン(PC)の内部温度測定などに使われる。
∴正解は選択肢4。
問題19 ★★
加速度センサーやジャイロセンサーに関する正しい説明。
- 回転するコマや光ファイバーなどで光のループをつくることで、加速度を検出することができる。
- MEMSを使った加速度センサーには、微細加工によって作成した重りと、それを支えるばねを備え、加速度による重りの変位を静電容量の変化や圧電素子で検出するものがある。
- カメラの手振れ防止機能では、加速度センサーでカメラのブレを検出し、レンズの傾きを制御している。
- 半導体で作成したジャイロセンサーは、MEMSを使って形成した回転するコマを備える。機械式ジャイロスコープと同じ原理で回転を検出する。
正解2
MEMSを使った加速度センサーでは、ばねで支持された重りのズレを静電容量や圧電素子で検出するものがある。なお、重りを使わない熱検知方式の加速度センサーもある。
∴正解は選択肢2。
回転コマを使った機械式ジャイロスコープや、光ファイバーや鏡を使って光を回転させる光学式ジャイロスコープは、物体の回転を検出。しかし、加速度を検出することはできない。
∴選択肢1は誤りです。
MEMSを使ったジャイロスコープは振動する物体に加わるコリオリの力を使って回転を検出。カメラの手振れ防止などに使われる。加速度センサーでは物体の回転を検出できない。
∴選択肢3と4は誤りです。
問題20 ★
米Rutgers Universityと米国国立標準技術研究所(National Institute of Standards and Technology: NIST)が定義したクラウドコンピューティングに関する誤った説明。
- クラウドから提供されるソフトウエアで、パソコンやスマートフォン、タブレット端末のどの環境からでもファイルを編集でき、クラウド上にファイルを保存できる。
- クラウドのサーバーのサービスを利用した際に、使用したCPUの使用率やメモリー量、ストレージのデータ量の消費量をブラウザー上ですぐに確認できる。
- クラウドから提供されるソフトウエアをダウンロードし、デスクトップアプリケーションとしてインストールすると、ライセンス認証時のみオンラインで、後はオフライン環境でも常時使用できる。
- 新しいクラウドのサーバーを立ち上げたいときに、CPUのコア数やメモリーの量、ディスク容量などをWebサイト上から選択すれば短期間で利用できる。
正解3
米Rutgers Universityと米国国立標準技術研究所(National Institute of Standards and Technology: NIST)が定義したクラウドコンピューティングの5つの特徴:
[1] オンデマンドのセルフサービス: ユーザーが必要なときに必要な分のサービスを利用できる。つまり、サービス事業者の人間を介さなくてもよい。 [2] 幅広いネットワークアクセス: ユーザーがパソコン(PC)だけではなく、スマートフォンやタブレット端末などからでも利用できる状態にある。 [3] リソースの共有: サーバーやストレージ、ソフトウエアなどの資源を複数のユーザーで共有できる。 [4] スピーディーな拡張性: ユーザーの要求に応じてシステムの拡張・縮小を即時に提供できる。 [5] サービスの計測可能性: ユーザーがサービスを利用した量を計測できる仕組みを持っている。選択肢1は[2]に当たる。ブラウザーさえあれば、基本的に端末(パソコン、スマートフォン、タブレット端末など)を選ばないということ。
選択肢2は[5]に該当します。従量課金制となっていることが多いため、実際の処理時間や容量などを確認しながらハードウエア(CPUやメモリー、ディスクなど)の増減を行うことが可能。
選択肢3は、一般的なデスクトップアプリケーションソフトウエアの説明。
選択肢4は[1]に当たる。サービスを利用する際に、サービス提供者側が作業を行うことなく、利用者が必要なときに必要な分だけ自動的に提供することが基本(セルフサービス)。
ただし、上記の5つの定義はあくまでもクラウドという言葉を説明するためにNISTが定義したもので、正式な規格でない。クラウドのサービス事業者やソフトウエアが「クラウド」と名乗る際に上記の項目から外れていても問題なし。
∴正解は選択肢3。
問題21 ★★★
下記の条件の場合、適切なクラウド。
自社の新しいWebサービスをクラウドベースのサーバーで始めたい。しかし、新しいサービスなので実際の利用者数や負荷が読めない状態である。そのため、まずは小規模な構成で初期コストをあまり掛けずに始めたい。過去の自社資産(ハードウエア、ソフトウエア、データ)やセキュリティーについては考慮しない。
- パブリッククラウド
- プライベートクラウド
- ハイブリッドクラウド
- コミュニティークラウド
正解1
選択肢1、リソースを他の利用者と共有し合うのがパブリッククラウド。多くの場合、データセンター事業者がリソースを提供。
選択肢2、プライベートクラウド=自社でリソースを占有し、専用のクラウドとして利用する社内のクラウドサービス。自社内でクラウドサーバーを構築。占有となるため、多くの場合、パブリッククラウドに比べて高額。
選択肢3、ハイブリッドクラウドは=クラウド環境をプライベートクラウドとパブリッククラウド、オンプレミスとパブリッククラウドなどの組み合わせで使う方法。例えば、過去の資産やセキュリティーなどを考慮してパブリッククラウドとプライベートクラウドを組み合わせたい場合は、ハイブリッドクラウド。
選択肢4、コミュニティークラウド=地方自治体同士や同種の業界の事業者などが共同で所有、あるいは運用するクラウドコンピューティング環境。
この問題では次の2つの条件があるため、パブリッククラウドが適している。
[1] セキュリティーなどについて考慮をする必要がない。 [2] 過去の自社資産などを使うことを検討しなくてもよい。∴正解は選択肢1。
問題22 ★★★
分散処理にはいくつか種類があります。このうち、オンメモリーで処理を行うApache Sparkが適していると思われる処理を選びなさい。
- T(テラ)バイト級以上の大容量のデータのバッチ処理。
- ツイートなどの短いデータのバッチ処理。
- メモリーに蓄積する必要がない処理。
- 1つのサーバーで扱えて、厳密な処理が必要な処理。
正解2
分散処理システムは、複数台のマシンで処理を分散して行う仕組みが必要になったことから生まれた。レコメンド(ショッピングサイトなどの購入履歴を基に商品などを推薦すること)やデータの分析といったビッグデータの処理を行うには、1台のマシンでは追いつかないから。
大量のデータを処理するには、ディスクに保存してから処理を行う方法と、メモリーに蓄積してから処理を行う方法があり、さらに、データを蓄積せずに即時処理を行う分散処理システムもある。
Apache Sparkはオンメモリーで実現する分散処理システム。データをディスクではなくメモリーにため込んで処理。メモリーに蓄積してすぐに処理するような、少容量データを次々と処理する場合に適性あり。例えば、ログの分析やレコメンド、検索、データマイニング、機械学習など。
逆に、メモリーに蓄積可能なデータを超えるか、それに近いT(テラ)バイトクラスの大容量データの処理には不向き。加えて、データを蓄積する必要性がないストリーム処理にも向不向き。
選択肢1について、大容量データの処理のため、Apache Sparkは不向き。
選択肢3について、オンメモリーで分散処理するApache Sparkには不向き。
選択肢4について、分散処理の必要がないため、通常のデータベース(リレーショナルデータベース管理システム: RDBMS)処理でOK。
∴正解は選択肢2。
問題23 ★★★★
Node.jsに関する誤った説明。
- 「クライアント1万台問題」に対応できる。
- フロントエンド(クライアントサイド)とパックエンド(サーバーサイド)の双方で同JavaScriptを使って記述することもできる。
- 大量のデータを処理するよりも、CPUが高負荷な処理に向いている。
- ApacheやNginxのよろなHTTPサーバーと同様に、Webアプリケーションサーバーである。
正解4
Node.jsは、Webサイトの構築やインターネットアプリケーションの開発に使うJavaScript言語をバックエンド(サーバーサイド)で動作できるようにするプラットフォーム(技術基盤)。Node.jsにより、フロントエンド(ユーザーインターフェース部分のソフトウェア)からバックエンド(ユーザーインターフェース部分からの入力に従ってサーバーで処理を行ったり、データベースにデータの保存処理などを行うソフトウエア)まで一貫して同じ言語を利用できるため、開発者の学習コストを下げることが可能。
選択肢1、「クライアント1万台問題」=アクセスするクライアントが1万を超えるあたりで発生する問題。Webサーバー(Apache)のスレッドが増えすぎてメモリーなどのリソースが不足するため、サーバーを増設しなければならないという問題が生じる。
例えば、10G(ギガ)バイトのメモリーを搭載したサーバーがあり、1スレッド当たり1M(メガ)バイトを消費すると仮定した場合、同時接続数は1万が限界。
選択肢2、Webのフロントエンド(ユーザーインターフェースなど)にJavaScriptを使うことが多いため、バックエンド側でもJavaScriptのコードを使用することができれば、フロントエンドに向けたコードを書いていたプログラマーもバックエンド側の処理コードを書ける(もしくは理解できる)ようになるというメリットあり。
選択肢3、Node.jsは基本的にシングルプロセス・シングルスレッドの動作が前提なので、高負荷な処理には不向き。ツイートのような短文を大量に受信して処理するような使い方に向いている。
選択肢4、Node.js自体はJavaScriptをサーバー側で動作させる技術基盤であり、Node.js自体はWebサーバーではない。
Node.js自体は短い大量のアクセスをさばく処理に向いているため、RESTfulなAPIを提供するWebサービスや「Twitter」のツイートのような小容量データの処理、オンラインシステムの統計データの生成など多数の接続があるものの、処理が軽いものに向いている。
∴正解は選択肢4。
問題24 ★★★
人工知能に関する誤った説明。
- 人工知能とは、人間が知能を使って行うことをコンピューターに模倣させようとする技術の総称。
- 人工知能の第1次期において、神経細胞を模した新たな学習手法が提案されたことで、学習分野は飛躍的に発展した。
- エキスパートシステムとは、ある分野に特化した専門知識データベースに基づいて、その専門家のように意思決定を行うコンピューター。
- 機械学習とは、計算機を使って無数のデータから分析方法や一般規則を導出する方法のこと。
正解2
人工知能の第1次期は1960年代まで遡る。1962年に米国の心理学者であるフランク・ローゼンプラット氏が神経細胞を模倣した学習手法を発表。この学習手法を現在は単純パーセプトロンと呼ぶ。しかし、1969年に単純パーセプトロンはXOR(排他的論理和)問題という単純な問題すら解けないという指摘により、停滞。
飛躍的な発展を遂げたのは、正しくは人工知能の第2次期。ニューラルネットワークの研究において、1986年に新たな学習手法が提案された。選択肢2は、「第1次期において飛躍的な発展を遂げた」と書かれているので誤りです。
∴正解は選択肢2です。
単純パーセプトロンは、データが散布された座標上のどこかに、関数に対応する1本の直線を引くことでデータの分類を行う手法。例えば、データを色によって分類する問題を考えたとき、図(a)のような場合は単純に1つの破線を引くことで問題を解くことが可能。しかし、図(b)のような場合は、任意の直線を1本引いたとしてもデータを分離できない。
人工知能とは、人間が知能を使って行うことをコンピューターに模倣させようとする技術の総称。従って、選択肢1は正しいため、この問題では誤りです。人工知能は、人間のような知能を持つロボットを作ることだと思うかもしれないが、実際の研究ではほとんど行われない。
エキスパートシステム=ある分野に特化した専門知識データベースに基づき、その分野の専門家のように意思決定を行うコンピューターのこと。つまり、選択肢3は正しい説明のため、この問題では誤りです。
「血液中のバクテリアの診断支援」は、医師と対話しているかのような質問応答機能が備わっていたこともあり、1970年代で最も影響力が大きかったエキスパートシステムといわれる。しかし、データベースの規模拡大におけるコストや専門知識を網羅的に獲得できないなどの理由で、研究段階の域を超えないシステムもあった。
機械学習=計算機を使って無数のデータから分析方法や一般規則を導出する方法のこと。従って、選択肢4は正しい説明のため、この問題では誤りです。
機械学習が盛んに研究されるようになった背景として、計算機資源の大容量化とインターネットの普及により、Web上から膨大なデータを収集・蓄積することが簡単になったことがある。
機械学習は解く問題の性質に基づき、[1]教師あり学習、[2]教師なし学習、[3]強化学習、の3つに大別される。近年では、ディープラーニングという機械学習の手法を使うことで、画像認識や自然言語処理などの分野で優れた結果が得られたとの報告も。
また、「AlphaGo」は教師あり学習と強化学習を組み合わせた囲碁の人工知能。2015年と2016年にプロの囲碁棋士を破った。
問題25 ★★★★★
囲碁の人工知能「AlphaGo」と「AlphaGo Zero」の登場により、近年脚光を浴びている機械学習に強化学習があります。強化学習に関する正しいもの説明。
- 与えられる報酬は、時間に依存しない。
- あらかじめ用意された手本に基づいて、ある状態でどのような行動が適切かを決定する学習手法である。
- 各状態における各行動の期待される報酬を推定する。
- 適応度に基づいて次に取るべき行動の取捨選択を行う。
正解3
図1は、強化学習の枠組み。エージェントとは行動を起こす主体であり、ゲームのプレイヤーやロボットを指す。エージェントは、環境の状態に基づいて何らかの行動を起こし、その行動によって環境が変化する。そして、その変化に応じてエージェントには報酬が渡される。報酬とは、目的達成のために得られた成果。例えば、格闘ゲームでは相手へのダメージ度合いが報酬であり、「強パンチ」という行動は「弱パンチ」よりも報酬が高い。また、報酬は状態に依存。自分が負けそうな局面では、パンチよりも相手から距離をとることや、防御する方が報酬が高くなる。エージェントは、環境に応じていろいろな行動を試すことで、ある状況において報酬の高そうな行動を学習する。
強化学習の目標は、エージェントが獲得する累積の報酬が最大になるような一連の行動の獲得。そのために、強化学習は各状態における各行動の期待される報酬を推定。
∴正解は選択肢3。
各手の期待報酬は、最後に得られる報酬から逆算して推定。ゲームの序盤では、ある状況でどのような行動に報酬を高く与えるかを推定することは難しいが、勝ち負けが決定した時点においては、勝つと10点、負けると-10点といった確定的な報酬を与えることが可能。次に、勝ち負けが決定する前の一手を考えると、勝ちにつながる一手の報酬が高くなることは想像できる。さらに、その前の手を考えると、その勝ちにつながる一手に遷移するような一手の報酬が高くなりそう。
このように、1つ先の期待される報酬を手掛かりとして、各状態における行動の報酬を推定(図2)。
強化学習は正解を与えず、どのような行動が適切かを試行錯誤しながら決定する学習手法なので、選択肢2は誤りです。ただし、囲碁の人工知能「AlphaGo」では、まず、強い人間の次の一手を予測する教師あり学習を使う。あくまでも一手先の予測なので、全体として勝ちにつながる一手かは不透明。次に、AlphaGoとその分身に強化学習を使って対局させ、最終的に勝ちにつながる一連の行動を獲得する。
各手の期待報酬を推定する際は、時間の経過とともに報酬を割引する。つまり、報酬は時間に依存するので、選択肢1は誤り。1回の行動で報酬が割引される割り合いを割引率といい、「γ」で表される。割引率は、0≦γ≦1の値。
割引を導入する理由には、報酬の高低に意味を持たせるため。図3のように割引を考慮しない場合、報酬の低い行動を地道に繰り返したときでも、報酬の総和を最大化できる。これに対して、報酬を割引したときには、そうした行動を繰り返したとしても報酬の総和は一定値に収束し、最大化できない。従って、報酬の価値を保つことができる。言い換えれば、報酬の割引は時間制限を導入している。
適応度は、遺伝的アルゴリズムにおいて解候補の良し悪しを評価するための関数なので、強化学習とは無関係。∴選択肢4は誤り。
問題26 ★
回帰分析において、正解値と予測値の2乗誤差の総和が最小になる回帰式を選択する方法。
- 最小二乗法
- 最短距離法
- 重心法
- ペアワイズ法
正解1
回帰分析は、予測対象のデータにうまく適合するような回帰式の係数を求める。例えば、線形の単回帰分析では、y=ax+bの係数a、bを決定します。正解値と回帰式による予測値の差の2乗和が最小となる係数を選択する方法=最小二乗法。
∴正解は選択肢1。
図は、差の2乗和の大小を比較、最小2乗法は、両者の差を辺とする正方形における面積の総和が最小となる直線を引くことと等価。
最短距離法は、クラスタリングにおけるクラスター間の距離を求める手法なので、回帰分析とは無関係。
∴選択肢2は誤り。
最短距離法は、2つのクラスターにおけるデータ間の距離で最も小さい距離を採用。
重心法は、クラスタリングにおけるクラスター間の距離を求める手法なので、回帰分析とは無関係。
∴選択肢3は誤り。
重心法は、クラスター内の重心を計算し、2つのクラスターにおける重心間の距離をクラスター間の距離とします。
ペアワイズ法は、SVMにおいてクラスが3つ以上の分類問題を扱う際に使われる方法です。回帰分析とは無関係。
∴選択肢4は誤り。
問題27 ★★
表は、農家の農作物の発育状態をまとめたもの。各属性の値における作物の発育状況の良し悪しを収集。これを学習データとして決定木を使って学習する場合、最初に選択するのが望ましい属性。
表(1918)

- 農家さんの年代
- 地域
- 気温
- 日照時間
正解3
優先的に選択される属性は、ある属性を使ってデータを分類したときに、分類後のノード全体でデータが特定のクラスに偏って含まれる属性。定量的な指標として情報利得やジニ係数が使われる。
図は、学習データを各属性で分類した結果。「気温」という属性に着目すると、「10」と「30」の条件で完全に異クラス同士のデータを分離できており、優先的に選択すべき属性。
∴正解は選択肢3。
「農家さんの年代」という属性は、全ての年代で異クラス同士のデータを分離できていないので、最初に選択すべき属性でない。
∴選択肢1は誤り。
「地域」という属性も「農家さんの年代」という属性と同様に、全ての地域で異クラス同士のデータを分離できていないため、最初に選択すべき属性でない。
∴選択肢2は誤り。
「日照時間」という属性は、「長い」という条件において異クラスのデータが均一に、かつ多くノード内に含まれたままなので、最初に選択すべき属性でない。
∴選択肢4は誤り。
問題28 ★★
ニューラルネットワークは、予測値と正解値の差が小さくなるようにニューロセル間の重みを逐次更新。重みを効率良く計算する方法に関する正しい説明。
- 既に求めた重みの更新結果を出力から入力層に向かって伝播させる。
- 全ての重みではなく、特定の確率で選択されたセル間における重みのみを更新する。
- 重みの初期値を適切に決定する。
- 事前確率を考慮する。
正解1
重みを効率良く更新する方法に、誤差逆伝播法がある。誤差逆伝播法は、既に求めた重みの更新結果を出力層から入力層に向かって伝播させる。
∴正解は選択肢1。
具体的には、誤差関数の傾きに基づいて以下の手順で重みを更新する。まず、出力と正解の差に基づいて誤差関数の傾きを計算し、「隠れ層1-出力層」間の重みを更新します。次に、左に移動し、隠れ層間の各重みを計算。「隠れ層2-隠れ層1」間における各重みの更新には、「隠れ層1-出力層」間の更新結果を部分的に使う。これを「入力層-隠れ層」間の更新まで繰り返す。
選択肢2は、深層学習におけるドロップアウトの説明。多層ニューラルネットワークのセルを確率的に選択することで学習する重みの数を減らし、過学習や深層学習の重大な問題である勾配消失問題を解決。つまり、効果的な重みの更新方法に関する説明。誤り。
選択肢3は、事前学習と呼ばれる勾配消失問題を解決する手段。誤り。
選択肢4は、経験や知識を反映させるための確率であり、ベイズ分析やベイジアンネットワークにおいて事後確率を求める際に使う。誤り。
問題29 ★
次の文章において(A)に当てはまる言葉。
情報セキュリティーにおける3大要素のうち、オープン化が前提となっている情報システムでは「機密性」が重視されている。これに対し、事業継続上の影響の大きい制御システムや、社会的な影響を及ぼしてその停止によって人命に関わるIoT機器では、(A)の担保が最重要とされている。
- 可用性(Availability)
- 完全性(Integrity)
- 真正性(Authenticity)
- 信頼性(Reliability)
正解1
製造プロセスの監視や制御によるデータ取得により、産業分野(Industry)におけるオペレーション効率を改善する手法としてIIoT(Industrial Internet of Things)が注目される。
IIoT環境では、公共エネルギーの供給や工場の製造ラインなど、システムの予期せぬ停止が甚大な被害となる環境も対象。「24時間365日の安定稼働」を続けるためには、必要な時点で情報に継続してアクセスできる特性である可用性(Availability)の担保が最重要事項。
∴正解は選択肢1。
選択肢2の安全性(Integrity)は、情報へのアクセス許可のある人だけが情報を利用でき、許可のない人には情報の使用や閲覧をできないようにする特性。IIoT環境では最も優先順位が低いとされている情報セキュリティーの3大要素。
選択肢3の真正性(Authenticity)は、ある主体または資源が、主張通りであることを確実にする特性。情報セキュリティーの3大要素ではなく、IIoT環境の安定稼働における最重要事項でない。
選択肢4の信頼性(Reliability)は、システムが持つ故障への耐性の度合いを示す特性。情報セキュリティーの3大要素でない。可用性と信頼性は混同しがち。信頼性が故障のしにくさ、可用性は使いたいときに使えること。例えば、極端に故障率の高い(壊れやすい)機器があったとしても、その機器の二重化を行うことにより、システム全体の可用性を高めることは可能。
問題30 ★
IoT機器における保守用インターフェースとして、TELNETサービスを立ち上げていた。同機器に対するIoTセキュリティー診断を受信した結果、パスワードの代わりに公開鍵認証を使えるリモートアクセス手段に置き換えることを求める指摘を受けた。この指摘事項に対する是正処置として、TELNETサービスが提供するサービスを損わずに利用できるプロトコル。
- FTPS(File Transfer Protocol over SSL/TLS)
- SCP(Secure CoPy)
- SFTP(SSH File Transfer Protocol)
- SSH(Secure Shell)
正解4
TELNETとは、ネットワークに接続された機器にリモートログインし、遠隔操作するために使用するプロトコル。標準ではTCP 23番ポートで待ち受けているサーバーと接続し、通信する。
TELNETは認証や通信内容を暗号化する仕組みがない。にもかかわらず、製品共通のIDとパスワードが設定されたままの状態で使用したり、開発者がメンテナンス用に残していたTELNETサーバーの存在を利用者が知らぬまま使用したりするIoT機器がある。
インターネットに接続されている機器を検索することができる「SHODAN」および「Censys」による検索結果によれば、日本国内で接続されている機器の多くがTCP 23番ポートで待ち受けている(図)。
攻撃者はこうした状況を踏まえ、脆弱なままで運用されているTELNETサービスを探索し、踏み台として悪用することで、犯罪に加担させる行為が確認される。
そこで、ユーザー名とパスワードを使用せずに、SSHクライアントが持つ秘密鍵とSSHサーバーが持つ公開鍵を使った認証により、リモートログインを許可できるSSHへの置き換えを推奨。
∴正解は選択肢4。
選択肢1のFTPS(File Transfer Protocol over SSL/TLS)は、SSLまたはTLSによる暗号化により、ファイルの送受信を安全に行うためのプロトコル。保守用インターフェースとして使用されていたTELNETサービスを置き換えるには不向き。
選択肢2のSCP(Secure Copy)は、SSHプロトコルによる暗号化により、ファイルの送受信を安全に行うためのプロトコル。保守用インターフェースのTELNETサービスを置き換えるには不向き。
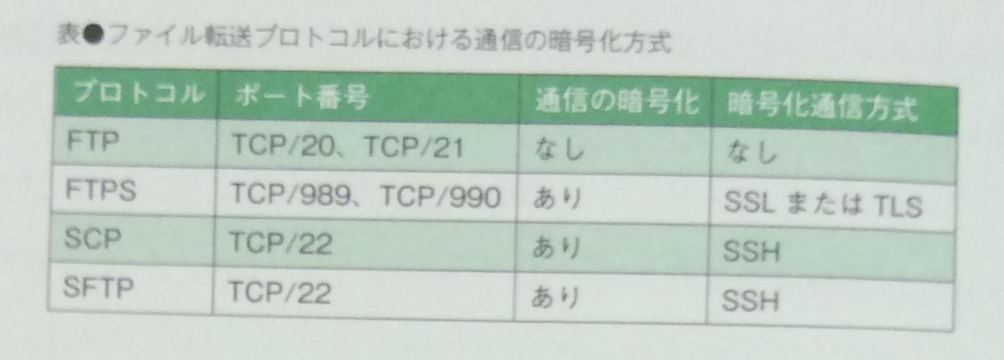
選択肢3のSFTP(SSH File Transfer Protocol)は、SSHプロトコルによる暗号化により、ファイルの送受信を安全に行うためのプロトコル。保守用インターフェースのTELNETサービスを置き換えるには不向き。FTPSとSCP、SFTPについて、それぞれの共通点と相違点を整理して理解すべき(表)。
表(1927)
問題31 ★★★
Webインターフェースを備えたIoT機器において、図が示す入力により、パスワード認証機構が迂回されたという報告を受けた。パスワード認証機構を迂回した正しい攻撃手法。
- CSRF(クロスサイトリクエストフォージェリー)
- OSコマンドインジェクション
- SQLインジェクション
- XSS(クロスサイトスクリプティング)
正解3
SQLインジェクション攻撃(CWE-89)とは、インジェクション攻撃(CWE-74)の一種。システムが利用者からの入力を受け付け、その内容からデータベースへの命令文を構成するデータ(SQLクエリ)を構築している場合に、設計者の意図しているSQLクエリを特殊な要素を組み込むことで細工し、データベースのデータを改ざんしたり不正に取得したりする攻撃。
問題の図はユーザー名とパスワードの入力を受け付けるWebフォームです。「ユーザー名:」の項目に「‘OR 1=1–」の文字列が入力される。
当該システムでは利用者からの入力内容からデータベースへの命令文を構築(図1、表)。
表(1930)

本来、設計者は、「ユーザー名(uid)」と「パスワード(pw)」の値をWebフォームから受け取り、「データベーステーブル(account_table)」内に一致するレコードがあった場合に、そのユーザー名を返答し、ユーザー名に基づいたログインを許可することを意図して設計。
問題中の図において、「‘OR 1=1–」が特殊な要素。この場合、次の命令文が構築される(図2)。

注目すべきは「WHERE」における条件式。まず、「‘」(単一引用符)は1つ前の「‘」と対「‘’」となることで、文字列定数が終了。
次に、「OR 1=1」はuidの値に関係なく検索条件を「常に真(Tautologies)」となるようにロジックの変更を行っている。
そして、最後の「–」によって文が完了し、構文エラーの原因となる残りのコードを「実行対象外のテキスト文字列(コメント)」と認識するように指定させる。
従って、「ユーザー名:」項目に「‘OR 1=1–」文字列が入力された場合は、パスワード認証機構の迂回が実現。
∴正解は選択肢3。
選択肢1のCSRF(クロスサイトリクエストフォージェリー、CWE-352)は、データ認証の検証が不十分な場合に攻撃者がクライアントを騙し、意図しないリクエストをWebサーバーに送信させて、Webサーバーはそのリクエストを正規のものとして取り扱うことで、データの漏えいや意図しないコードの実行を招く攻撃。画面が示す入力からは、攻撃者が細工した罠のリンクなどは確認されません。∴誤り。
選択肢2のOSコマンドインジェクション(CWE-78)は、インジェクション攻撃(CWE-74)の一種です。システムが利用者からの入力を受け付け、その内容からOSコマンドの全部、もしくは一部を構築している場合、設計者の意図しているOSコマンドを改ざんし、許可されていないコードやコマンドを実行する立要。画面が示す入力からは、攻撃者によるOSコマンドの入力などは確認されない。∴誤りです。
選択肢4のXSS(クロスサイトスクリプティング、CWE-79)は、インジェクション攻撃(CWE-74)の一種。ユーザーからの入力に対する無害化を適切に行わないまま、他のユーザーに提供するWebページの出力に含めて、悪意あるスクリプト(簡易的なプログラム)をクライアント側で実行する攻撃。画面が示す入力からは、攻撃者による悪意あるスクリプトなどは確認されない。∴誤り。
問題32 ★
二要素認証の正しい組み合わせ。
- 指紋と虹彩(アイリス)
- パスワードと合言葉(本人しか知り得ない情報)
- パスワードとハードウエアトークン
- パスワードとユーザー名
正解3
ユーザー名とパスワードの組み合わせによる認証は、本人のみが知っている記憶/知識(SYK: Something You Know)に基づいて同一性を確認する手段。汎用性が高く実装コストが安価であり、何より多くの人にとってイメージしやすいため、ほとんどのシステムで採用される。
しかし、パスワードは相互に正しい相手先を確認するための認証システムとして、必ずしも最良の方法でない。これまでパスワードの盗難により、数多くのデータ盗難があり、記憶に頼った認証情報は忘却の可能性あり。
そこで、種類の異なる2つ以上の要素を組み合わせて認証する二要素認証の利用が注目される。アクセス制御における識別を行うための要素には、記憶/知識(SYK)の他に、所持(SYH: Something You Have)、生体(SYA: Something You Are)の2つ。
問題の選択肢では、記憶/知識(SYK)に関するパスワードと、本人のみが所持(SYH)しているハードウエアトークンが、複数の要素を組み合わせることにより、保護技術の層に厚みを持たせる。
∴正解は選択肢3。
選択肢1の「指紋と虹(アイリス)」は、いずれも生体(SYA)に関する情報を組み合わせて認証を行う。このため、二要素とはいえない。
選択肢2の「パスワードと合言葉(本人しか知りえない情報)」は、いずれも記憶/知識(SYK)に関する情報を組み合わせて認証を行う。このため、二要素とはいえない。
選択肢4の「パスワードとユーザー名」は、記憶/知議(SYK)に基づく情報と事前に相手先を識別(Identification)するための固有情報による認証。このため、二要素とはいえない。
問題33 ★
SIEMの正しい説明。
- 監視対象のファイルについてあらかじめ基準値を作成しておき、現状との比較を行うことでその整合性について監視を行うシステム。
- 機器のさまざまなログを収集・格納し、検索性を高めて可視化することによって、セキュリティー上の脅威となる事象の分析を支援するシステム。
- 信頼できるネットワークと信頼できないネットワークの境界に配置し、事前に定義されたルールに基づいてパケットの通過を制御するためのシステム。
- ネットワークに流れる通信のデータ本体(ペイロード情報)を監視し、異常を検知した場合に管理者へ通知するなどの処置を行うシステム。
正解2
SIEM(Security Information and Event Management)は、リアルタイムのセキュリティー情報とイベントの管理に主眼を置いた総合ログ管理ツール。厳格な定義はないが、一般にはログの「収集」「格納」「検索」「可視化」「分析」という5つの機能も持つ。ログ分析を行うログサーバーと、ログを格納するデータベースサーバーによって構成。SIEMは、複数種のログ生成元に対応。生成元から得たデータを分析し、ログ項目間のイベントについて相関処理を行うことにより、セキュリティー上の脅威となる事象の分析を支援するシステム。
∴正解は選択肢2。
選択肢1は、改ざん検知システムの1つである、ファイル整合性監視(FIM: File Integrity Monitoring)の記述。
選択肢3は、アクセス制御システムの1つである、ファイアウオール(Firewall)の記述。
選択肢4は、侵入検知システム(IDS: Intrusion Detection System)の1つである、NIDS(Network-Based IDS)の記述。
